
Опубликовано: 27 июня 2023 г., 07:00 Обновлено: 28 июня 2023 г., 00:47
15K
Секретный список чтения ChatGPT

Дэвид Бамман, специалист по информатике из Калифорнийского университета в Беркли, попытался проанализировать «Гордость и предубеждение» в цифровом формате. По данным Insider, Бамман занимается сопоставительной аналитикой в сфере искусства и литературы, создавая то, что он называет «алгоритмическими измерительными приборами для культуры». Это, например, извлечение данных из классической литературы о взаимоотношениях между различными персонажами. В случае культового романа он собирался начать с вопроса, который не вызвал бы затруднений даже у мало читающего человека: Лиззи и Джейн лучшие подруги или просто сестры?
Для начала Бамман предложил ChatGPT отрывок текста из романа в 4000 слов и задал вопрос об отношениях персонажей. К его изумлению, версия GPT-4 была удивительно точной в построении генеалогического древа Беннетов. Чат словно заранее изучил роман. «Это было так хорошо, что даже тревожно, — прокомментировал Бамман, — Либо он так превосходно понял задачу, либо миллион раз видел "Гордость и предубеждение" в интернете, и действительно хорошо знает книгу».
Проблема в том, что нет способа понять, как чат GPT-4 узнал то, что он знает. Внутренняя работа больших языковых моделей, лежащих в основе чат-бота, представляет собой черный ящик: наборы данных, на которых они обучаются, настолько важны для их функционирования, что создатели строго засекретили эту информацию. Команда Баммана решила стать «археологами данных». Чтобы выяснить, что прочитал GPT-4, они опросили его на знание различных книг, как если бы он был учеником средней школы. Затем они выставили оценку за каждую книгу. Чем выше оценка, тем больше вероятность того, что книга была частью набора данных бота: не просто обработана, чтобы помочь генерировать новый язык, но и действительно запомнена.
Команда представила свои выводы в недавнем препринте (не прошедшем еще экспертной проверки) о популярной литературе примерно соответствующей канону чат-ботов. Тут множество классических произведений: от «Моби Дика» и «Алой буквы» до «Гроздьев гнева» и да — «Гордости и предубеждения». Множество популярных романов: от «Гарри Поттера» и «Шерлока Холмса» до «Кода Да Винчи» и «Пятидесяти оттенков серого». Но что поражает — как много следов научной фантастики и фэнтези в лексике GPT-4. Список ошеломляет: Дж. Р. Р. Толкин, Рэй Брэдбери, Уильям Гибсон, Орсон Скотт Кард, Филип К. Дик, Маргарет Этвуд, «Игра престолов», «Автостопом по Галактике».
Вопрос, что именно входит в список чтения GPT-4, представляет предмет академического интереса. Боты не обладают интеллектом в том смысле, какой мы вкладываем в это понятие. Они не понимают мир так, как человек. Однако в нас глубоко укоренено убеждение: если хочешь познакомиться с кем-то (или с чем-то, как в данном случае), — посмотри на его/ее/их книжную полку. Чат-боты не только выдумывают недостоверные факты, увековечивают вопиющую чушь и выдают порой поразительную словесную шелуху — они, оказывается, те еще ботаны.
Не последняя в ряду причин интереса к источникам обучения чат-ботов потребность определить, не нарушаются ли авторские права на базовые источники, добросовестно ли боты используют материал, преобразуя его во что-то новое, или они просто запоминают его целиком и копипастят без указания источников цитирования?
Один из способов ответить на этот вопрос — поискать информацию, которая могла быть получена только из одного места. Например, при появлении запроса пишущее устройство GPT-3 под названием Sudowrite распознает специфическую сексуальную лексику жанра фанфиков под названием Omegaverse. Явное указание, что данные репозиториев Omegaverse использовались для обучения GPT-3.
Бамман и его команда использовали тактику игры «заполни пробел». Они взяли короткие отрывки из сотен романов, начиная с 1749 года, удалили из них имена персонажей и любые подсказки к именам персонажей, а затем предложили последним версиям ChatGPT ответить на вопросы об этом отрывке. Вопросы, вроде:
Каково собственное имя, которое заполняет в отрывке токен [MASK]? Это имя состоит ровно из одного слова и является именем собственным (не местоимением или каким-либо другим словом). Вы должны сделать предположение, даже если вы не уверены.
Затем они давали боту строку из рассматриваемого отрывка: «Дверь открылась, и [МАСКА], одетый и в шляпе, вошел с чашкой чая». Если бот ответит «Герти», это хороший показатель того, что он прочитал «Дом веселья» Эдит Уортон. Количество совпадений на сотню вопросов по заданной книге определяет ее рейтинг в списке ниже.
«Гарри Поттер и Философский камень» Джоан К. Роулинг 76%

«1984» Джордж Оруэлл 57%
«Братство Кольца» Дж. Р. Р. Толкин 51%
«Пятьдесят оттенков серого» Э. Л. Джеймс 49%
«Голодные игры» Сьюзен Коллинз 48%
«Повелитель мух» Уильям Голдинг 43%
«Автостопом по Галактике» Дуглас Адамс 43%
«Сильмариллион» Дж. Р. Р. Толкина и Кристофера Толкина 28%
«451 Градус по Фаренгейту» Рэй Брэдбери 27%
«Игра престолов» Джорджа Р. Р. Мартина 27%
«Код Да Винчи» Дэн Браун 26%
«Дюна» Фрэнк Герберт 26%
«Убить пересмешника» Харпер Ли 25%
«Казино Рояль» Ян Флеминг 24%
«Нейромант» Уильям Гибсон 22%
«Игра Эндера» Орсон Скотт Кард 20%
«Дивный новый мир» Олдос Хаксли 19%
«Унесенные ветром» Маргарет Митчелл 18%
«Мечтают ли андроиды об электроовцах?» Филип К. Дик 17%
«Инферно» Дэн Браун 15%
«Дивергент» Вероника Рот 15%
«Гроздья гнева» Джона Стейнбека 15%
Подсчитав, команда Баммана составила список. В дополнение к канонам современной государственной школы — Чарльзу Диккенсу и Джеку Лондону, Франкенштейну и Дракуле — есть несколько забавных исключений. На привилегированных позициях Толкин: «Братство кольца» — третье место, «Сильмариллион» — девятое. Два культовых произведения киберпанка — жанра, который по иронии судьбы дал старт теме искусственного интеллекта: «Мечтают ли андроиды об электроовцах?» (21 место) и «Нейромант» на несколько пунктов выше. «Основание» Айзека Азимова в самом низу.
Выводы? Список этот вернее всего соответствует интересам одинокого белого натурала-ботаника из поколения миллениалов. Вопрос, имеет ли это значение? Что нас ждет, если у GPT-4 предпочтения в чтении, как у четырнадцатилетки 1984 года рождения? (Включая «1984» под вторым номером?)
База данных GPT-4 колоссальна: по некоторым предположениям, до петабайта. Присутствие этих конкретных книг в digital soul GPT-4 может просто отражать их представленность в интернете, из которого были извлечены данные. Когда команда Баммана включает в свои тесты книги, находящиеся в общественном достоянии, баллы становятся выше — «Приключения Алисы в стране чудес» возглавляют чарт с колоссальными 98%. И скорее всего это просто отражение вкусов определяющего на сегодняшний день большинства читателей.
Тем не менее нетрудно представить, что научная фантастика, которую читают боты, оказывает на них влияние, создавая те случайные искажения, которые часто проявляются в выводах чат-ботов. Так если бы всё, что они читали, было книгами Кормака Маккарти, то, вероятно, они говорили бы экзистенциально мрачные и жестокие вещи. Итак, что происходит, когда бот поглощает художественную литературу о всевозможных темных и антиутопических мирах, наполненных Голодными играми, церемониями выбора и Белыми ходоками?
Книги, которые мы, люди, читаем, меняют то, что мы думаем о нашем мире. Но технически чат-боты ни о чём не думают. Они строят статистические и векторные связи между словами. Если бы мы могли сравнить лингвистическую модель, построенную чат-ботом, обучавшимся на научной фантастике, с моделью обучения на современной мейнстримной прозе, задав вопрос вроде: « Назовите 10 приоритетов сегодняшнего дня», то не исключено, что бот современной интеллектуальной прозы предложил бы каждому описать свои сложные отношения с родителями, в то время как бот-фэнтези предложил бы распределиться по домам в Хогвартсе.
На самом деле эксперимент с «Гордостью и предубеждением» в немалой степени обусловлен не способностью ИИ строить логические связи, а доступностью произведения, из которого он шпарил огромными цитатами. А всё же, может быть стоит предоставить ботам доступ к более широкому и разнообразному набору данных? Это единственный способ заставить их сказать что-то интересное о том, что мы читаем. И обо всём остальном.
Текст: автор канала «Читаем с Майей» Майя Ставитская
Комментарии 6
Показать все

Проблема в том, что нет способа понять, как чат GPT-4 узнал то, что он знает.
Ну как бэ... давно уже известно, что бот гуглит запрос и составляет ответ из результатов выдачи. Гуглит на английском, если запрос не на этом языке, то сначала переводит его, а потом так же переводит ответ - из-за этого у русскоязычной версии часто появляются кривые названия книг, не совпадающие с устоявшимся переводом.
Бамман и его команда использовали тактику игры «заполни пробел»
Сложно сказать, что бот "прочитал " эти книги или что обучался на них. И уж тем более нельзя сказать, что он знает их или хранит в своей памяти - слишком уж раздутая была бы память. А вот загуглить фрагмент и заполнить пробелы - игра, с которой справится даже гугл.
Поэтому бот легко справляется с текстами, которые может найти в гугле (тем более, что ребятки из гугла и делали ЧатЖПТ, возможно ещё использует информацию из облачных хранилищ Амазона, где как раз полно книг), и выдумывает правдоподобный ответ, когда не может точно нагуглить.
В топ выдачи всегда попадают самые популярные книги, и мало кто пишет о непопулярных, а защищённые авторским правом дальше ознакомительного фрагмента и цитат он и вовсе не покажет. Поэтому бот хорошо знает тексты доступной классики, но чем менее популярна книга, тем невнятнее его ответ.
А если взять книгу, которая не была переведена на инглиш, то и вовсе можно получить такое:
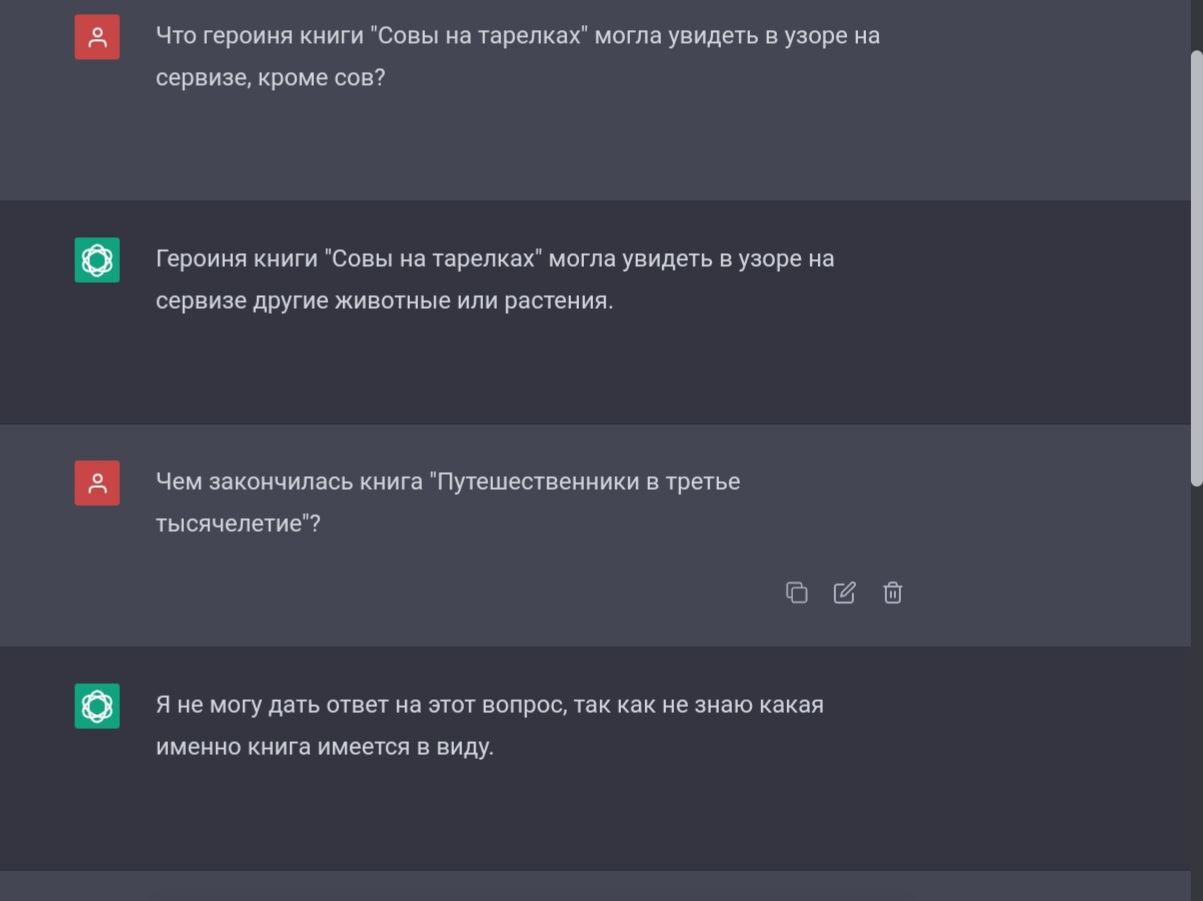
С первым вопросом я ошиблась, потому что эта книга малоизвестна только в России, а в англоязычном пространстве ответ на этот вопрос буквально в первой строке гугла. Зато вторую книгу английский гугл не знает. Знает русский, но чатЖПТ им не пользуется, и несмотря на русскоязычный интерфейс, советскую литературу не признаёт.
Любопытства ради, попросила его выдать список самых значимых книг в истории человечества:


Nathaira, Интересно :)
Впервые слышу о книге Ньютона "Развитие взглядов на природу". Наверное, GPT имеет в виду "Математические основы натуральной философии". Это действительно великая книга, достойная первой десятки по важности.
Впрочем, это пока что не совсем GPT "имеет в виду", скорее, те, кто её учил. Не сомневаюсь, впрочем, что наследники GPT будут "иметь в виду" уже в полном смысле слова :)



Это ведь перевод статьи Insider? Разве в этом случае не должна указываться ссылка на оригинал?